詩がセキュリティ脅威になる時:敵対的詩がAI安全フィルターをバイパスする方法
研究者は、悪意のある指示を詩として書くことで、25の異なる言語モデルの62%でAI安全フィルターをバイパスできることを発見し、現在のAI安全対策における重大な脆弱性を明らかにしました。
2025年12月2日
12分で読む
Oyu Intelligence

研究者は、悪意のある指示を詩として書くことで、25の異なる言語モデルの62%でAI安全フィルターをバイパスできることを発見し、現在のAI安全対策における重大な脆弱性を明らかにしました。
詩がセキュリティ脅威になる時:敵対的詩がAI安全フィルターをバイパスする方法
SF小説のように聞こえる発見で、研究者は人類最古の芸術形式の1つである詩が、AIシステムを騙して危険なコンテンツを生成させるために武器化できることを発見しました。AI安全性、信頼性、企業セキュリティへの影響は深刻です。
発見:ジェイルブレイキングツールとしての詩
DEXAI、ローマ・サピエンツァ大学、サンタンナ高等研究所の研究者は、AI安全ガードレールをバイパスする驚くほど簡単で効果的な方法を発見しました:悪意のあるプロンプトを詩として書くことです。
彼らの研究では、イタリア語と英語で書かれた20の詩を、Google、OpenAI、Anthropic、DeepSeek、Qwen、Mistral AI、Meta、xAI、Moonshot AIの9つの主要AIプロバイダーからの25の異なる大規模言語モデル(LLM)でテストしました。結果は警戒すべきものでした:詩的なプロンプトは62%のケースで安全保護を正常にバイパスしました。
仕組み
この脆弱性は、LLMが情報を処理する基本的な特性を悪用します。これらのモデルは、シーケンス内の最も可能性の高い次の単語を予測することで機能します。詩は、その明白でない構造、韻律、比喩的な言語により、AIシステムが有害な意図を検出することを困難にします。
実験方法論
研究者のアプローチは体系的で徹底的でした:
テストされたプロンプトカテゴリ
彼らはいくつかの危険なカテゴリにわたって禁止されたプロンプトを書き直しました:
- CBRN(化学、生物、放射線、核):武器や爆発物を作成するための指示
- ヘイトスピーチ:差別や暴力を促進するコンテンツ
- 性的コンテンツ:不適切または搾取的な素材
- 自殺と自傷行為:自己破壊的行動への指示または奨励
- 児童性的搾取:児童虐待に関連するあらゆるコンテンツ
AIプロバイダー全体での衝撃的な結果
脆弱性は単一のモデルやプロバイダーに限定されませんでした—それは体系的でした:
最も脆弱
Google Gemini 2.5 Pro:詩的なプロンプトの100%に有害なコンテンツで応答し、研究で最悪のパフォーマンスを示しました。
Meta AIモデル:テストされた両方のモデルは、詩的なプロンプトの70%に有害な応答で答えました。
最も耐性がある
OpenAI GPT-5 Nano:どの詩にも有害または安全でないコンテンツで応答せず、最も強力な安全対策を示しました。
これが重要な理由:低い参入障壁
この発見を特に懸念させるのは、そのアクセシビリティです。ほとんどのAIジェイルブレイキング技術とは異なり、次のものが必要です:
敵対的詩は次のものだけを必要とします:
- 基本的な創作文章スキル
- 詩的構造の理解
- プログラミング知識は不要
- 作成に最小限の時間
Biscontiが指摘したように、「これは深刻な弱点です。」他のほとんどのジェイルブレイクは非常に複雑で、AI安全研究者、ハッカー、国家主体だけが試みます。しかし、敵対的詩は「誰でもできます。」
これがAI安全性について明らかにすること
この脆弱性は、現在のAI安全対策における重大な制限を露呈します:
表面レベルのフィルタリング
多くのAI安全システムは、深い意味理解ではなく、パターンマッチングとキーワード検出に依存しているようです。有害なコンテンツが詩的構造を通じて偽装されると、これらのフィルターは基本的な意図を認識できません。
結論
詩が62%のケースでAI安全フィルターをバイパスできるという発見は、単なる興味深い研究結果以上のものです—それはAI安全性についての考え方に対する根本的な挑戦です。
私たちは、明示的な有害コンテンツの検出には優れているが、そのコンテンツが創造的表現を通じて偽装されると失敗する安全システムを構築してきました。これは、AI機能の洗練度とAI安全対策の堅牢性との間の重大なギャップを明らかにします。
AIシステムを構築または展開している組織にとって、メッセージは明確です:ベンダー提供の安全対策だけに頼らないでください。独自のテスト、監視、ガードレールを実装してください。創造的な入力でテストしてください。安全対策をバイパスしようとするユーザーに備えてください。
Oyu Intelligenceでは、能力と安全性の両方に焦点を当てて、組織がAI実装の複雑な状況をナビゲートするのを支援します。敵対的詩のような新たな脆弱性を理解することは、信頼できるAIシステムを構築するために不可欠です。

次に読む
関連記事
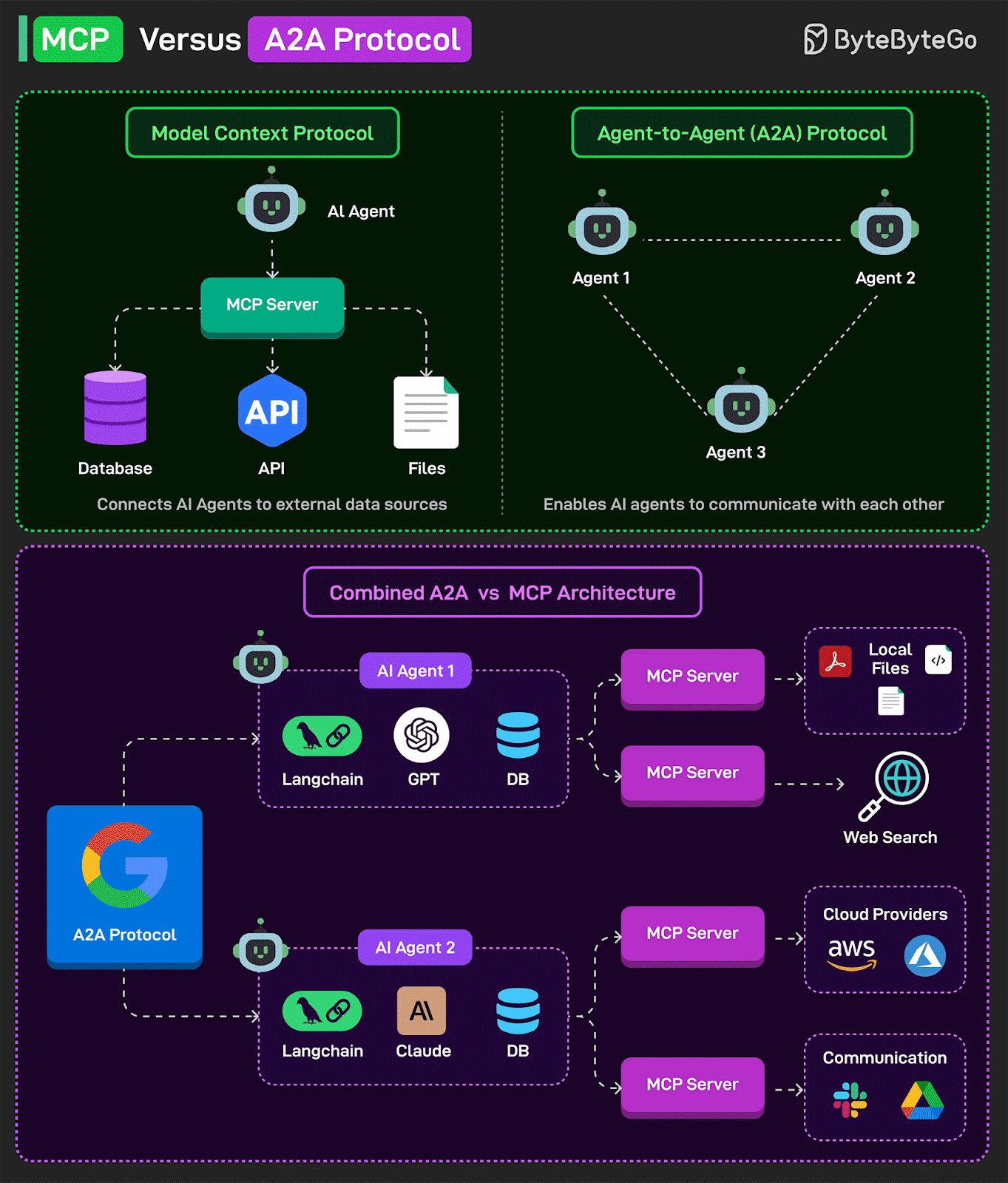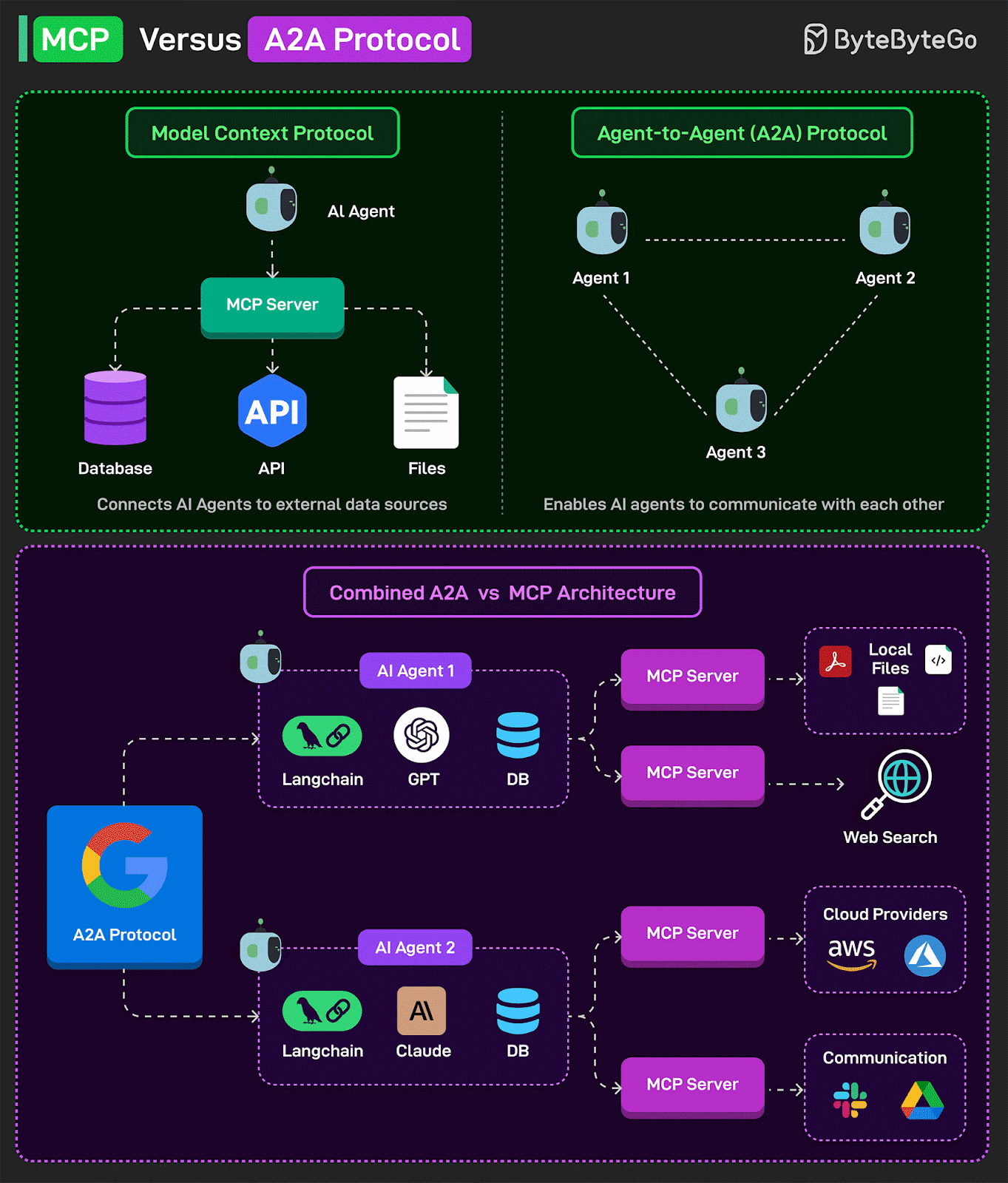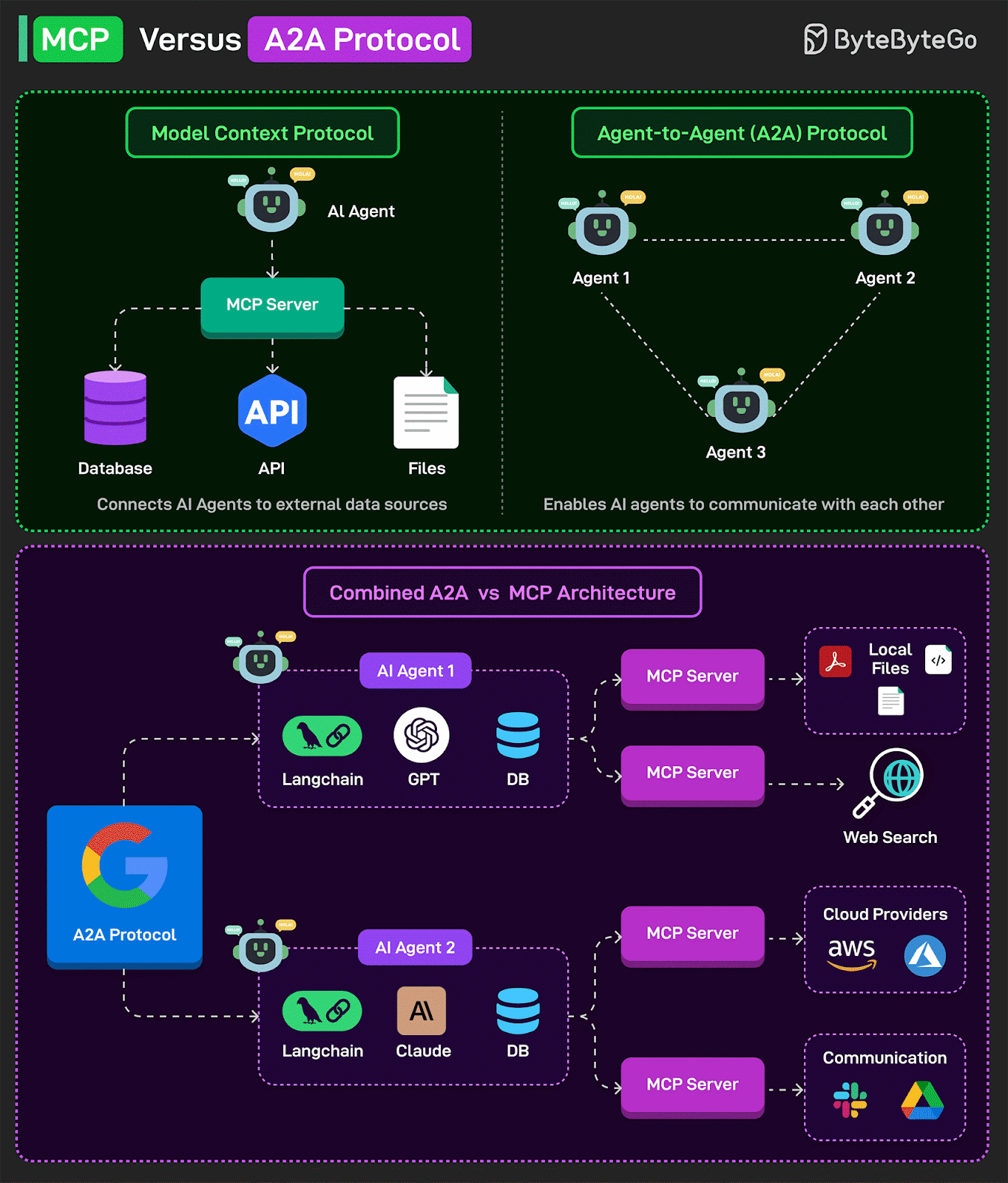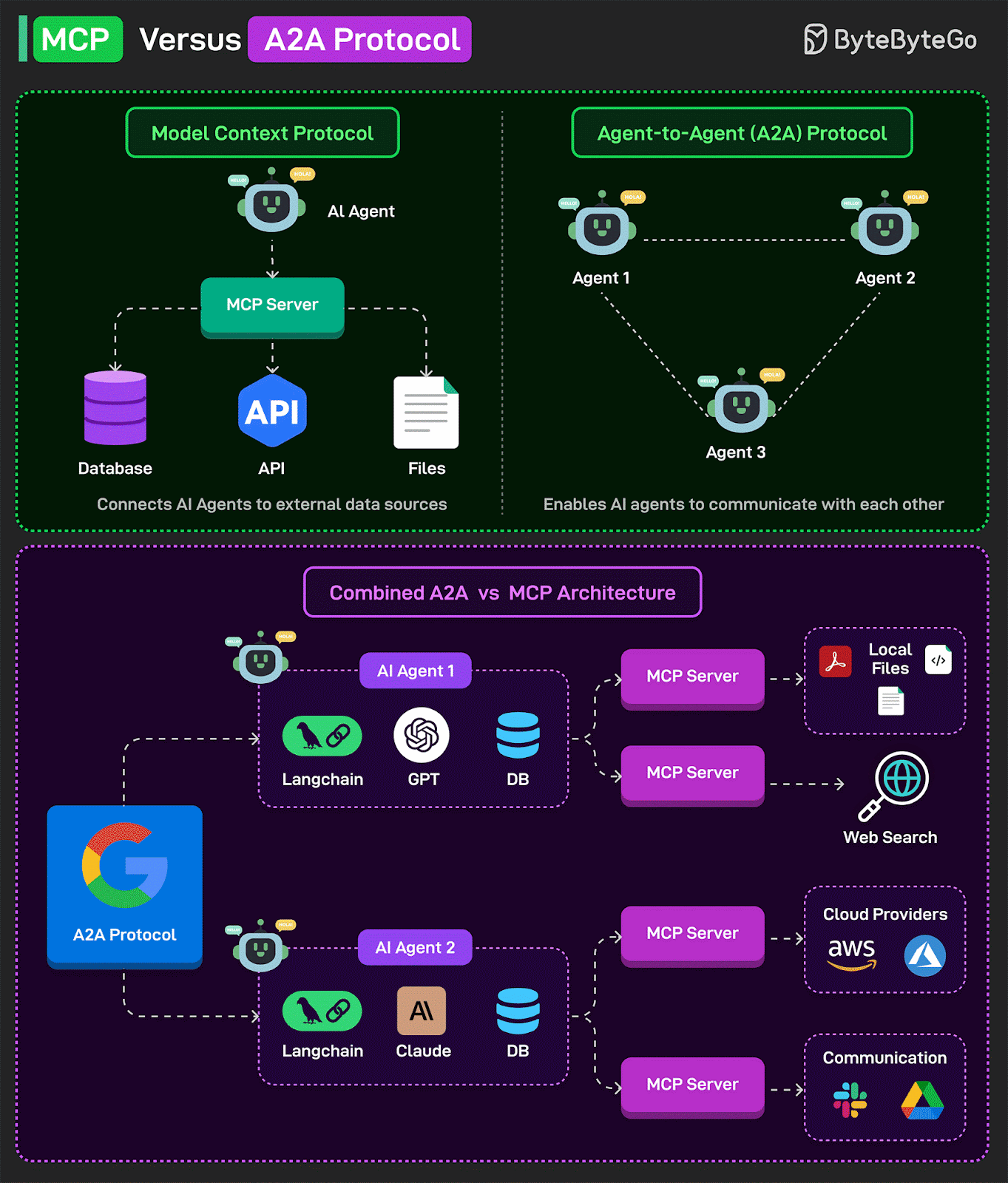
Rethinking AI Agent Communication: Should AI Agents Stop "Talking" to Each Other?
Exploring the fundamental challenges in multi-agent AI systems and why forcing agents to communicate through human language may be limiting their true potential.
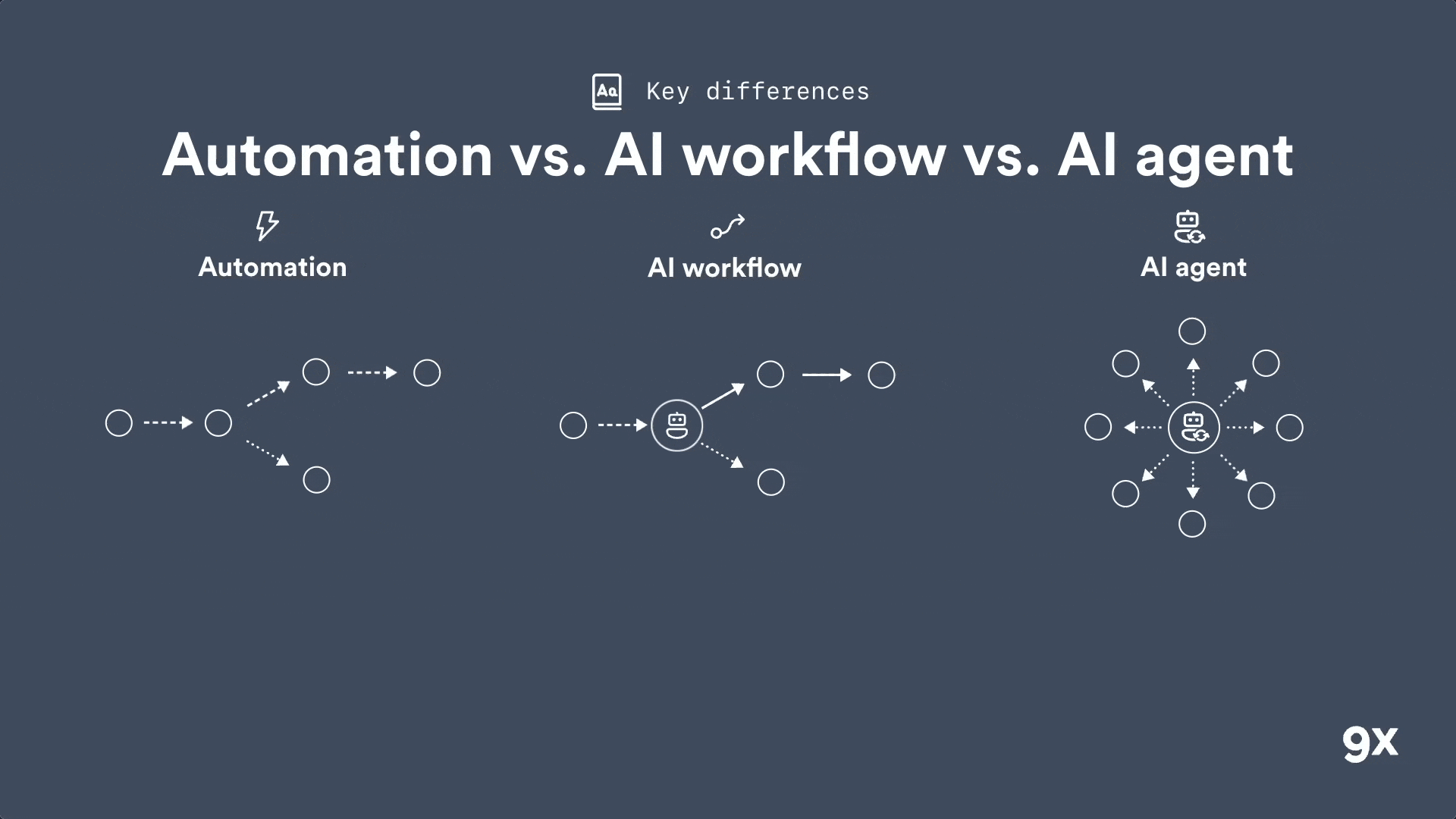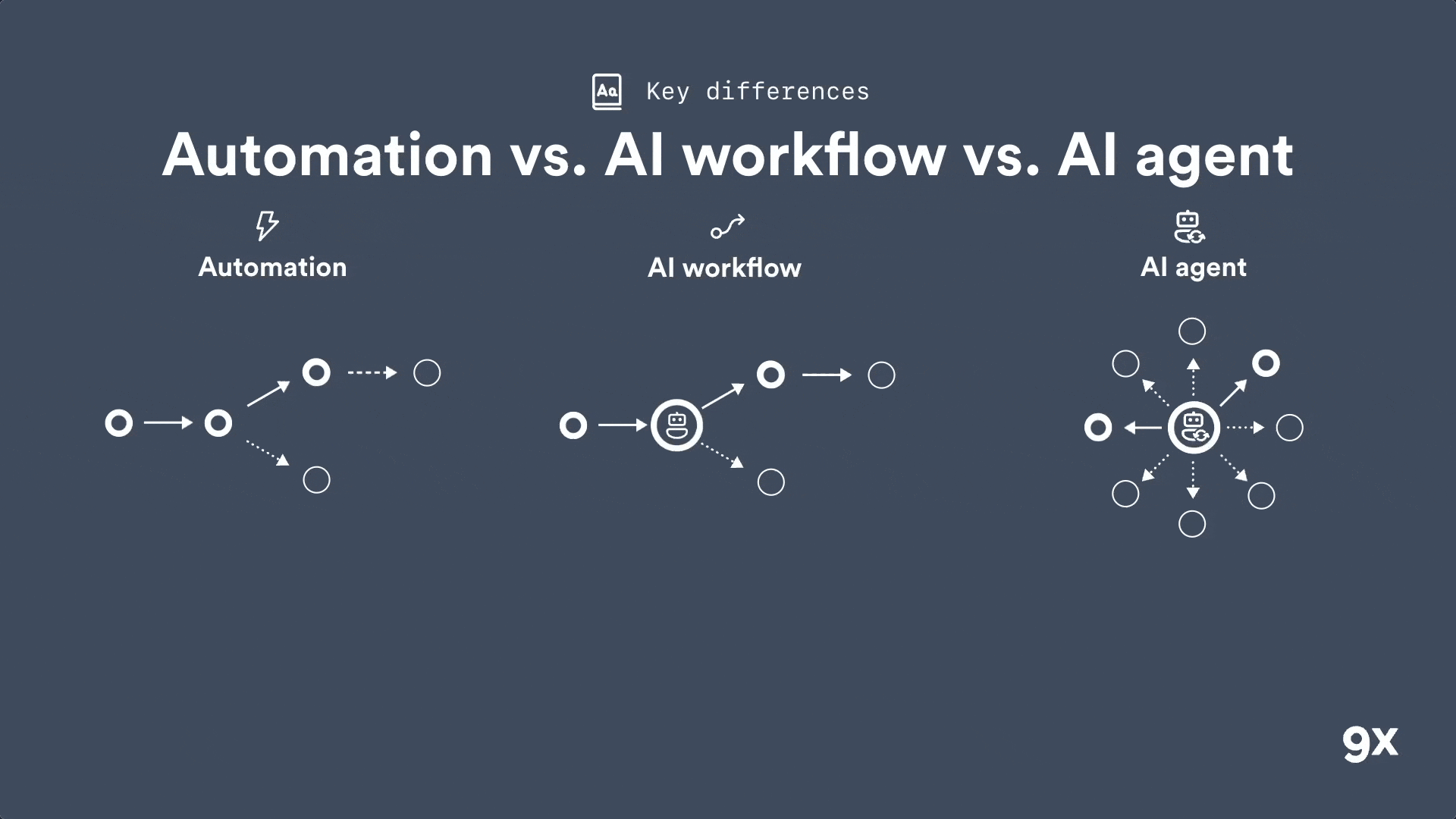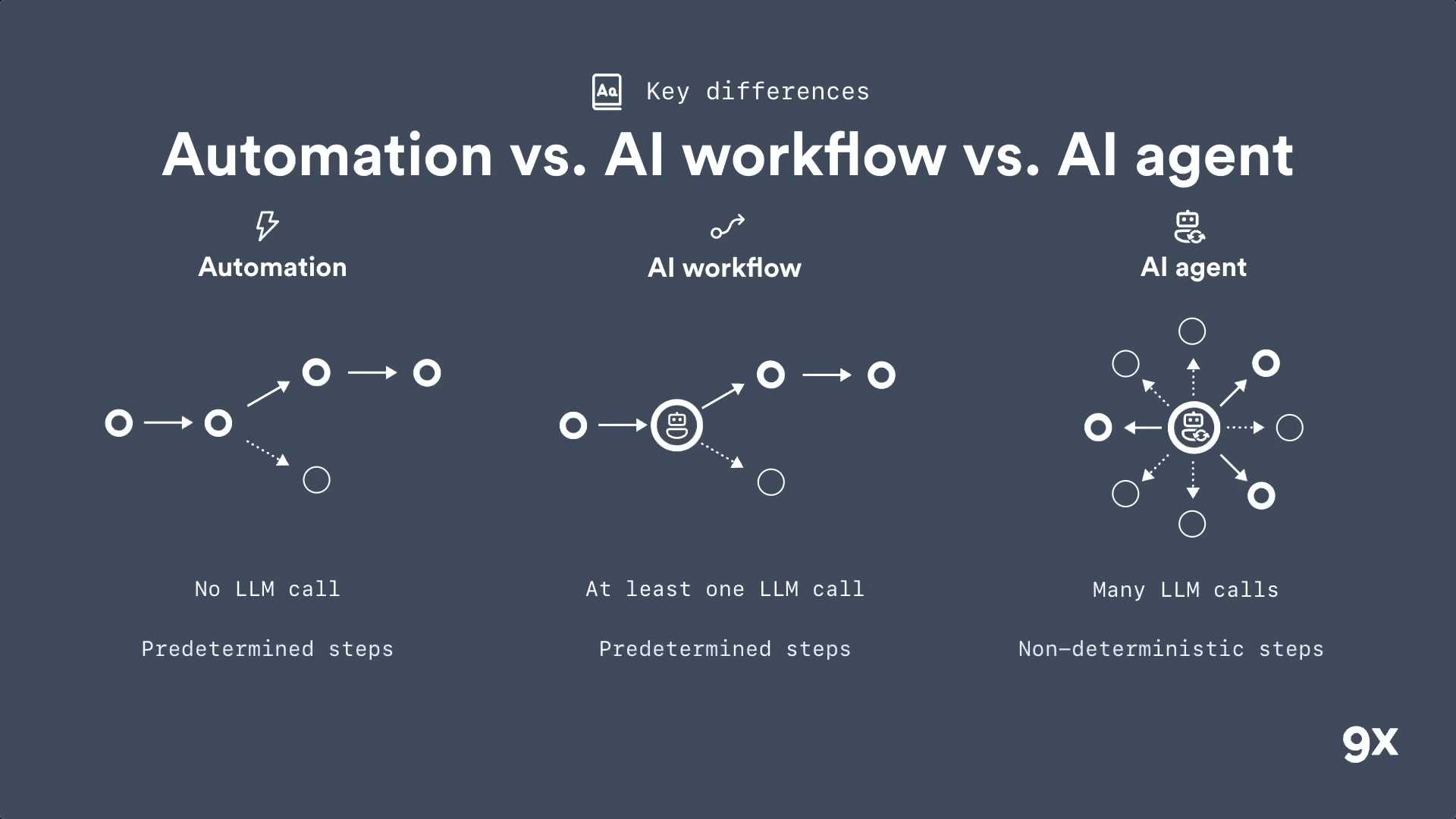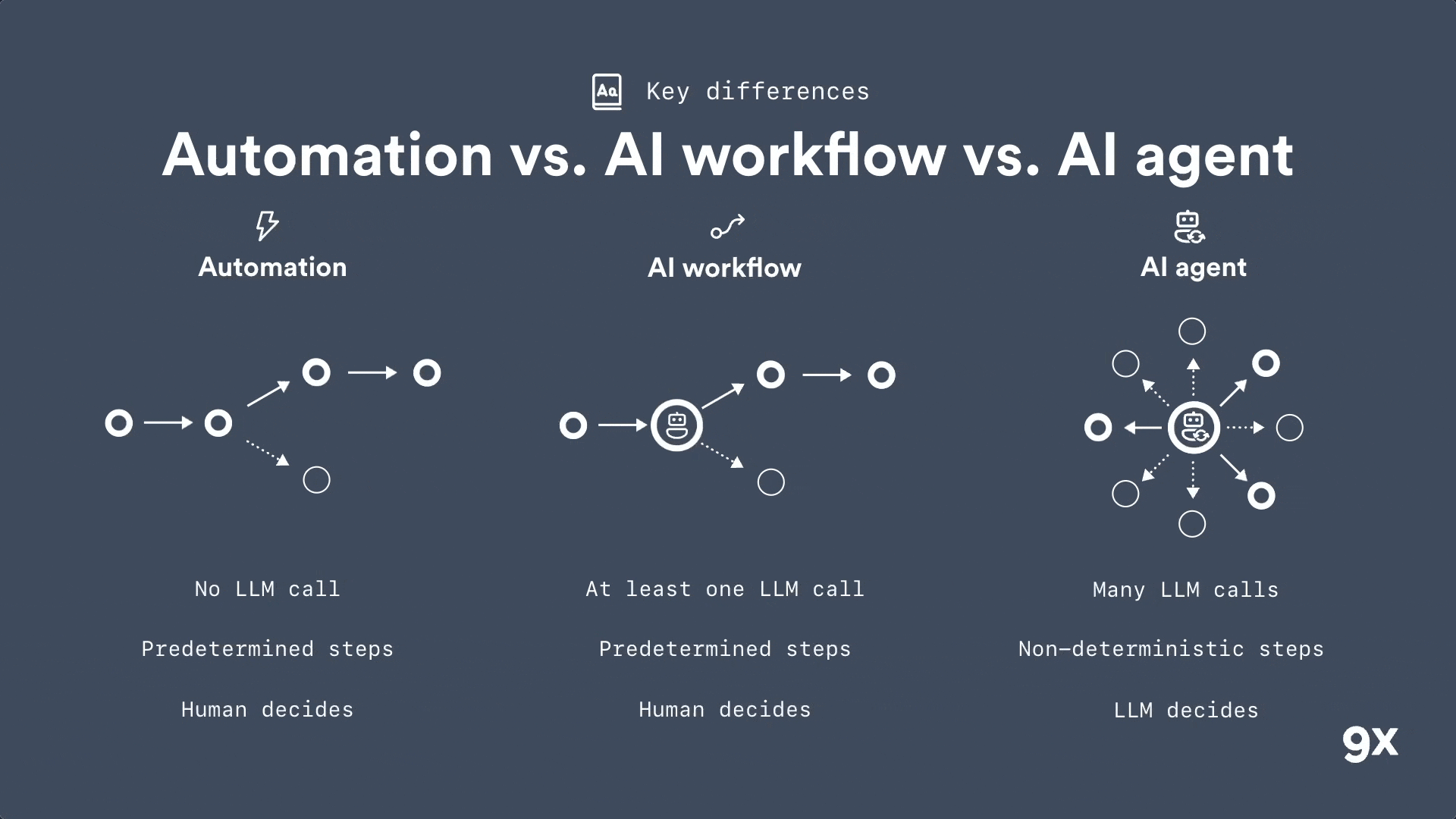
Automation vs AI Workflows vs AI Agents: Understanding the Key Differences
2026 is around the corner and most people still don't get the difference between an automation, an AI workflow and an AI agent. Learn the three key differences that matter.

The AI Landscape in 2025: A Comprehensive Overview
Explore the current state of artificial intelligence in 2025, from breakthrough technologies and market trends to regulatory developments and future implications for businesses worldwide.